Introduction to UniMoE-Audio
A Unified Speech and Music Generation with Dynamic-Capacity Mixture of Experts
UniMoE-Audio
UniMoE-Audio is a unified framework that seamlessly combines speech and music generation. Powered by a novel dynamic-capacity Mixture-of-Experts design, it adapts intelligently to input complexity, enabling high-fidelity voice and expressive music within a single model.
UniMoE-Audio introduces a dynamic-capacity routing mechanism based on Top-P sampling for adaptive expert allocation, together with a hybrid expert design that separates domain-specific computation (dynamic experts) from universal representations (shared experts). To address data imbalance and task conflicts, UniMoE-Audio adopts a structured three-stage training curriculum. From voice cloning and text-to-speech (TTS) to text-to-music (T2M) and video-text to music (VT2M), UniMoE-Audio supports diverse creative workflows. Extensive experiments confirm its state-of-the-art performance and superior cross-task synergy, paving the way toward universal audio generation.

Left: Our model overcomes the performance degradation of naive joint training, achieving synergistic gains.
Right: It demonstrates competitive performance against leading models on comprehensive speech and music metrics.
Fig. 1 Performance of UniMoE-Audio
On the left of Fig. 1, comparison against specialized baselines reveals the failure of naive joint training, which causes a clear performance degradation on speech generation and more significant decline on music generation. The root of this problem lies in the divergent objectives of speech and music tasks as well as severe data imbalances, which make naive joint training incapable of capturing their inherent complexity.
In contrast, UniMoE-Audio yields synergistic gains across both tasks. On radar charts in Fig. 1, UniMoE-Audio is shown achieving competitive performance against leading models on a wide array of speech (a) and music (b) metrics.
A Novel Dynamic-capacity MoE for Mitigating Task Conflict
To provide adaptive allocation of computational resources between simple and complex tasks, the model's architectural core is a Transformer enhanced with Dynamic-Capacity Mixture-of-Experts (MoE) layers. The following Fig. 2 shows the overall architecture of UniMoE-Audio.
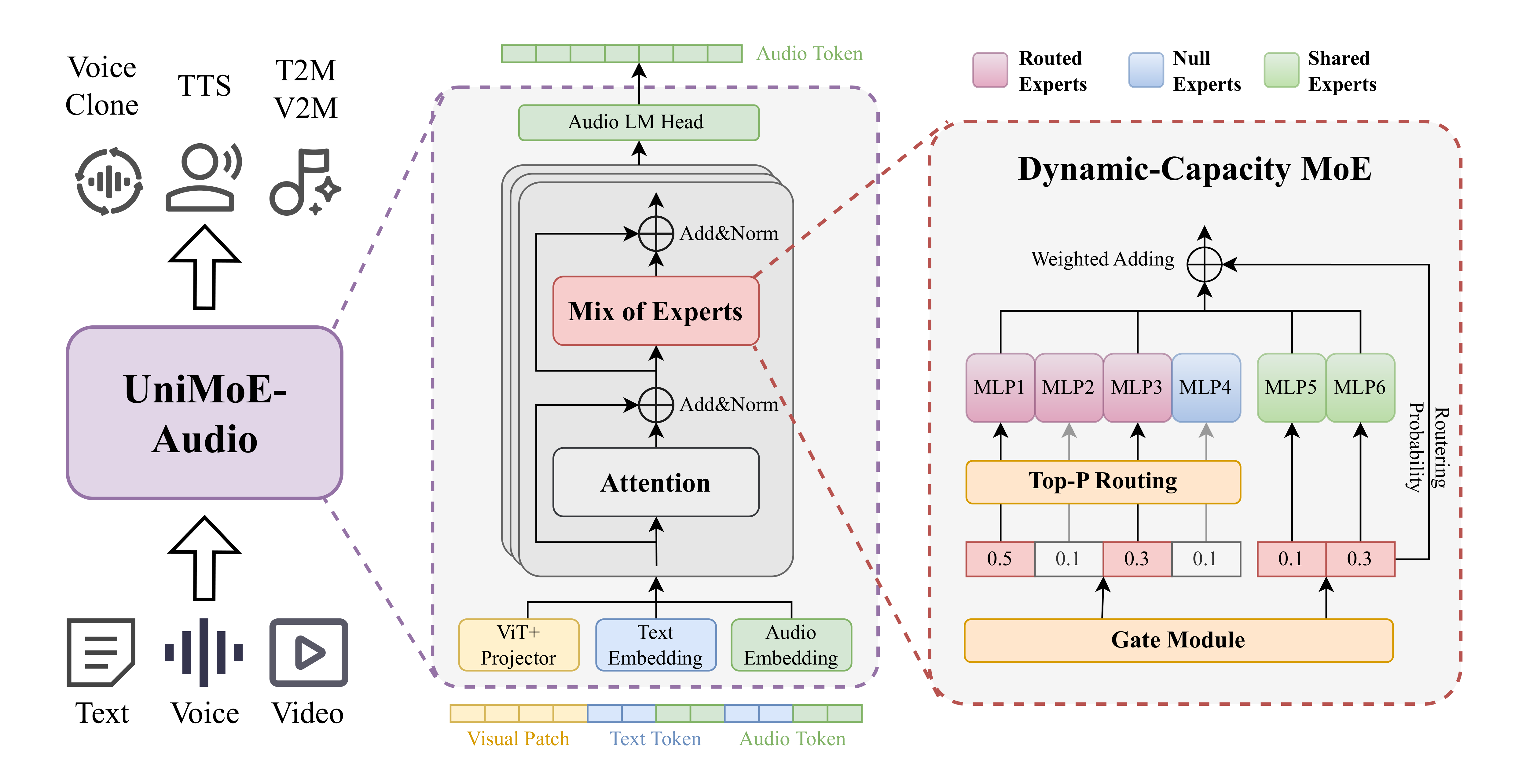
Left: The UniMoE-Audio unified architecture for speech and music generation from multimodal conditions.
Right: The proposed Top-P routing strategy for dynamic expert allocation based on token complexity.
Fig. 2 UniMoE-Audio Structure
Crucially, we introduce a Top-P routing strategy that overcomes the limitations of conventional static Top-K routing. Instead of assigning a fixed number of experts to every token, our approach dynamically determines the number of experts based on the complexity of each token. This ensures that simple tokens do not consume unnecessary resources, while complex tokens are granted sufficient processing power, resulting in improved overall efficiency and performance.
Moreover, we employ a three-stage training curriculum to enable effective joint learning from imbalanced data. This process—comprising independent specialist training, integration with warm-up, and synergistic joint training—successfully overcomes the challenges of data imbalance and task conflict. (Details can be found in the paper) paper
Experiment Results
We evaluate UniMoE-Audio against state-of-the-art specialized models for speech and music generation. The results, summarized in Table 1, Table 2 and Table 3, demonstrate that our single, unified model not only avoids the performance degradation typical of naive joint training but achieves competitive or even superior results in both domains.
Speech Synthesis
Speech Synthesis (TTS) converts text into natural and fluent speech, focusing on clarity, naturalness, and speaker characteristics.
| Method | SeedTTS-EN | SeedTTS-ZH | Librispeech | AISHELL-3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WER↓ | UTMOS↑ | SIM↑ | CER↓ | UTMOS↑ | SIM↑ | WER↓ | UTMOS↑ | CER↓ | UTMOS↑ | |||||
| UniAudio | 0.072 | 3.46 | 0.40 | - | - | - | 0.183 | 3.26 | - | - | ||||
| Mini-CPM-O-2.6 | 0.034 | 3.49 | 0.36 | 0.130 | 2.94 | 0.47 | 0.111 | 3.76 | 0.131 | 3.30 | ||||
| Qwen-Omni | 0.021 | 4.16 | - | 0.016 | 3.28 | - | 0.076 | 4.19 | 0.025 | 3.38 | ||||
| Step-audio | 0.022 | 3.84 | 0.52 | 0.010 | 3.23 | 0.62 | 0.050 | 4.37 | 0.027 | 3.69 | ||||
| UniMoE-Audio | 0.019 | 4.36 | 0.56 | 0.008 | 3.73 | 0.65 | 0.044 | 4.23 | 0.016 | 3.86 | ||||
Across multilingual benchmarks including SeedTTS, LibriSpeech, and AISHELL-3, UniMoE-Audio leads across all metrics, with WER as low as 0.019 and UTMOS up to 4.36 (3.86 for Chinese), outperforming UniAudio, Qwen-Omni, and others. This indicates superior speech clarity, naturalness, and speaker consistency.
Text to Music Generation
Text-to-Music Generation (T2M) transforms text descriptions into music clips, evaluating the model's ability to capture melody, rhythm, and atmosphere.
| Dataset | Task | Metric | Models | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YuE | Stable Audio | AudioX | MuGen | MUMU-LLAMA | UniMoE-Audio | |||||||||
| MusicCap | T2M | PC↑ | 3.45 | 3.70 | 5.00 | 4.78 | 5.15 | 6.00 | ||||||
| PQ↑ | 7.25 | 7.29 | 6.67 | 7.37 | 7.71 | 7.77 | ||||||||
| CE↑ | 5.84 | 6.02 | 6.14 | 6.57 | 6.87 | 7.34 | ||||||||
| CLAP↑ | 0.18 | 0.30 | 0.25 | 0.26 | 0.20 | 0.29 | ||||||||
| KL↓ | 2.12 | 1.44 | 1.20 | 1.21 | 1.27 | 1.39 | ||||||||
| CLaMP3↑ | 0.09 | 0.11 | 0.12 | 0.10 | 0.10 | 0.12 | ||||||||
| IS↑ | 2.09 | 2.74 | 3.02 | 1.68 | 1.44 | 1.93 | ||||||||
| FAD↓ | 9.02 | 3.72 | 1.64 | 7.02 | 8.57 | 6.43 | ||||||||
| V2M-bench | T2M | PC↑ | 3.78 | 3.41 | 4.60 | 4.64 | 5.19 | 5.75 | ||||||
| PQ↑ | 7.25 | 7.46 | 7.30 | 7.37 | 7.73 | 7.58 | ||||||||
| CE↑ | 6.01 | 5.69 | 6.06 | 6.24 | 6.75 | 6.85 | ||||||||
| CLAP↑ | 0.15 | 0.34 | 0.30 | 0.28 | 0.17 | 0.31 | ||||||||
| KL↓ | 1.27 | 1.91 | 2.12 | 1.27 | 0.92 | 1.06 | ||||||||
| CLaMP3↑ | 0.13 | 0.16 | 0.11 | 0.15 | 0.13 | 0.19 | ||||||||
| IS↑ | 1.79 | 3.13 | 3.64 | 1.70 | 1.42 | 2.17 | ||||||||
| FAD↓ | 4.29 | 2.94 | 4.26 | 3.39 | 2.54 | 3.11 | ||||||||
On both MusicCap and V2M-bench, UniMoE-Audio achieves the best performance across key metrics such as PC, PQ, and CE (e.g., PC=6.00, PQ=7.77, CE=7.34 on MusicCap), outperforming strong baselines. This shows its ability to generate music with clear melody, coherent rhythm, and high perceptual quality.
Video-Text to Music Generation
Video-to-Music Generation (VT2M) generates music aligned with video content, testing cross-modal alignment and emotional expression.
| Dataset | Task | Metric | Models | |
|---|---|---|---|---|
| AudioX | UniMoE-Audio | |||
| V2M-bench | VT2M | PC↑ | 4.44 | 5.88 |
| PQ↑ | 7.44 | 7.62 | ||
| CE↑ | 6.06 | 6.96 | ||
| KL↓ | 1.84 | 1.69 | ||
| IS↑ | 3.14 | 3.31 | ||
| FAD↓ | 2.94 | 2.89 | ||
On V2M-bench, UniMoE-Audio significantly outperforms AudioX, reaching PC=5.88, PQ=7.62, and CE=6.96, while remaining competitive on diversity metrics like FAD. This demonstrates stronger capability in aligning video content with contextually fitting music, highlighting its cross-modal generation strength.
Performance
Speech Generation
| Male Chinese 1 | 夕阳慢慢沉下,城市的喧嚣逐渐远去,只剩下心跳和呼吸。我走在熟悉的街道,脚步与记忆轻轻相碰,像一首未完的歌。 |
|
我们基于动态容量混合专家框架,构建了一个统一语音和音乐生成模型。 |
|
| Male Chinese 1 | 生活是一场旅行,每一步都值得被记住。放慢脚步,嗅闻花香,听见自己的心声。勇敢走出去,你会遇见更大的世界。 |
|
今夜星光闪闪,我爱你的心满满,想你一晚又一晚,把爱你的心都填满。 |
|
| Male Chinese 2 | 知道曙光何时来,我打开每一扇门,是如鸟有羽,还是如岸有涛。 |
|
有时候慢下来,认真感受生活,反而会发现更多的美好。 |
|
| Male Chinese 2 | 命无增无减,我们不再去留意时间,不再匆匆忙忙,宛若树木和星辰。 |
|
哈尔滨工业大学历史悠久。新中国成立以来,在党的领导下,学校扎根东北、爱国奉献、艰苦创业,打造了一大批国之重器,培养了一大批杰出人才,为党和人民作出了重要贡献。 |
|
| Female Chinese 1 | 如果查尔斯继承王位,卡米拉将获得王后称号。 |
|
机场工作人员和驻场武警,连夜在机场跑道上扫雪除冰。 |
|
| Male English 1 | This large sea duck is characterised by its bulky shape and large bill. |
|
After this album was released, Steve Roach embarked on a second trip to Australia. |
|
| Male English 2 | We propose UniMoE-Audio, a unified speech and music generation model based on a novel dynamic-capacity Mixture-of-Experts framework. |
|
The nature reserve covers only a small part of the marsh area. |
|
| Male English 2 | The nature reserve covers only a small part of the marsh area. |
|
After this album was released, Steve Roach embarked on a second trip to Australia. |
|
| Male English 3 | My wars are laid away in books, I have one battle more, a foe whom I have never seen. |
|
A hallmark of human intelligence is the seamless ability to perceive, reason, and create across multiple modalities, effortlessly blending language, vision, and audio. |
|
| Male English 3 | How happy is little stone that rambles in the road alone and don't care about carrers. |
|
No matter how rough the road ahead is, keep moving and you will eventually see new horizons. |
|
Music Generation
| Piano | This is a chill, melodic house track with a driving beat and dreamy synth textures. Perfect for relaxing or background listening. |
|
| Latin | This song contains several drum hits and percussive instruments playing a fast paced rhythm that motivates dancing along. An e-bass is bringing the low end supporting the drums. Cuatro guitars are strumming chords as a rhythmic addition. Trumpets are playing a loud and catchy melody. Some of the musical elements are slightly panned to the left and right side of the speakers. This song may be playing at a cheerful event. |
|
| Electronic | This song contains a digital drum playing a simple pattern with a kick and a snare sound. Synthesizers are playing a repeating melody in the higher register. Another synth sound is playing a more aggressive lead sound with a countermelody. A string sample is being used to create a short hit. This song may be playing during a car ride. |
|
| Electronic | This is a four on the floor style of production. The song is a drum and bass type of song with a bright and fuzzy synth to add a melodic element. The first part of the song feels suspenseful. |
|
| Rock | This is a rock music piece. There is a medium-to-high pitched electric guitar solo at the forefront. In the melodic background, a keyboard and a bass guitar repeating the same pattern can be heard. The acoustic drums are playing a loud and slightly fast-paced rock drum beat. There is a rebellious atmosphere to this piece. It can be used in the soundtrack of a teenage drama or a crime shootout audio game. |
|
|
|
A calming instrumental piece featuring acoustic guitar, creating a peaceful and relaxing atmosphere. Ideal for meditation or background music. |
|
|
|
This is an energetic funk instrumental driven by a catchy, clean electric guitar riff that creates an immediate sense of fun and groove. A tight, punchy drum beat and a driving, melodic bassline lock together to form an irresistible rhythmic foundation. The overall mood is upbeat, feel-good, and exciting, making it perfect for a fast-paced, dynamic video that showcases satisfying actions. |
|
|
|
A high-octane electronic piece, featuring pulsating synth chords and a powerful four-on-the-floor kick drum that creates a driving, relentless pace. |
|
Explore more comprehensive examples and advanced features in our detailed showcase.
View Full Showcase